
Umum
Apakah EvalSavedModel masih diperlukan?
Sebelumnya TFMA mengharuskan semua metrik disimpan dalam grafik tensorflow menggunakan EvalSavedModel khusus. Sekarang, metrik dapat dihitung di luar grafik TF menggunakan implementasi beam.CombineFn .
Beberapa perbedaan utamanya adalah:
-
EvalSavedModelmemerlukan ekspor khusus dari pelatih sedangkan model penyajian dapat digunakan tanpa memerlukan perubahan apa pun pada kode pelatihan. - Ketika
EvalSavedModeldigunakan, metrik apa pun yang ditambahkan pada waktu pelatihan secara otomatis tersedia pada waktu evaluasi. TanpaEvalSavedModelmetrik ini harus ditambahkan kembali.- Pengecualian terhadap aturan ini adalah jika model keras digunakan, metrik juga dapat ditambahkan secara otomatis karena keras menyimpan informasi metrik di samping model yang disimpan.
Bisakah TFMA berfungsi dengan metrik dalam grafik dan metrik eksternal?
TFMA memungkinkan pendekatan hibrid digunakan di mana beberapa metrik dapat dihitung dalam grafik sedangkan metrik lainnya dapat dihitung di luar. Jika saat ini Anda memiliki EvalSavedModel maka Anda dapat terus menggunakannya.
Ada dua kasus:
- Gunakan TFMA
EvalSavedModeluntuk ekstraksi fitur dan penghitungan metrik, tetapi juga menambahkan metrik berbasis penggabung tambahan. Dalam hal ini Anda akan mendapatkan semua metrik dalam grafik dariEvalSavedModelbersama dengan metrik tambahan apa pun dari berbasis penggabung yang mungkin belum didukung sebelumnya. - Gunakan TFMA
EvalSavedModeluntuk ekstraksi fitur/prediksi tetapi gunakan metrik berbasis penggabung untuk semua penghitungan metrik. Mode ini berguna jika terdapat transformasi fitur diEvalSavedModelyang ingin Anda gunakan untuk pemotongan, namun lebih memilih untuk melakukan semua penghitungan metrik di luar grafik.
Pengaturan
Tipe model apa yang didukung?
TFMA mendukung model keras, model berdasarkan API tanda tangan TF2 generik, serta model berbasis estimator TF (meskipun bergantung pada kasus penggunaan, model berbasis estimator mungkin memerlukan EvalSavedModel untuk digunakan).
Lihat panduan get_started untuk daftar lengkap jenis model yang didukung dan batasan apa pun.
Bagaimana cara mengatur TFMA agar berfungsi dengan model berbasis keras asli?
Berikut ini contoh konfigurasi model keras berdasarkan asumsi berikut:
- Model yang disimpan adalah untuk penyajian dan menggunakan nama tanda tangan
serving_default(ini dapat diubah menggunakanmodel_specs[0].signature_name). - Metrik bawaan dari
model.compile(...)harus dievaluasi (ini dapat dinonaktifkan melaluioptions.include_default_metricdalam tfma.EvalConfig ).
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Lihat metrik untuk informasi selengkapnya tentang jenis metrik lain yang dapat dikonfigurasi.
Bagaimana cara mengatur TFMA agar berfungsi dengan model berbasis tanda tangan TF2 generik?
Berikut ini adalah contoh konfigurasi untuk model TF2 generik. Di bawah, signature_name adalah nama tanda tangan spesifik yang harus digunakan untuk evaluasi.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
Lihat metrik untuk informasi selengkapnya tentang jenis metrik lain yang dapat dikonfigurasi.
Bagaimana cara menyiapkan TFMA agar berfungsi dengan model berbasis estimator?
Dalam hal ini ada tiga pilihan.
Opsi 1: Gunakan Model Penyajian
Jika opsi ini digunakan maka metrik apa pun yang ditambahkan selama pelatihan TIDAK akan disertakan dalam evaluasi.
Berikut ini contoh konfigurasi dengan asumsi bahwa serving_default adalah nama tanda tangan yang digunakan:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Lihat metrik untuk informasi selengkapnya tentang jenis metrik lain yang dapat dikonfigurasi.
Opsi2: Gunakan EvalSavedModel bersama dengan metrik berbasis penggabung tambahan
Dalam hal ini, gunakan EvalSavedModel untuk ekstraksi dan evaluasi fitur/prediksi dan juga tambahkan metrik berbasis penggabung tambahan.
Berikut contoh konfigurasinya:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Lihat metrik untuk informasi selengkapnya tentang jenis metrik lain yang dapat dikonfigurasi dan EvalSavedModel untuk informasi selengkapnya tentang menyiapkan EvalSavedModel.
Opsi3: Gunakan Model EvalSavedModel hanya untuk Ekstraksi Fitur/Prediksi
Mirip dengan opsi (2), tetapi hanya menggunakan EvalSavedModel untuk ekstraksi fitur/prediksi. Opsi ini berguna jika hanya metrik eksternal yang diinginkan, namun ada transformasi fitur yang ingin Anda potong. Mirip dengan opsi (1) metrik apa pun yang ditambahkan selama pelatihan TIDAK akan disertakan dalam evaluasi.
Dalam hal ini konfigurasinya sama seperti di atas hanya include_default_metrics yang dinonaktifkan.
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
Lihat metrik untuk informasi selengkapnya tentang jenis metrik lain yang dapat dikonfigurasi dan EvalSavedModel untuk informasi selengkapnya tentang menyiapkan EvalSavedModel.
Bagaimana cara mengatur TFMA agar berfungsi dengan model berbasis keras model-to-estimator?
Pengaturan keras model_to_estimator mirip dengan konfigurasi estimator. Namun ada beberapa perbedaan khusus tentang cara kerja model dan estimator. Secara khusus, model-ke-esimtator mengembalikan keluarannya dalam bentuk dict di mana kunci dict adalah nama lapisan keluaran terakhir dalam model keras terkait (jika tidak ada nama yang diberikan, keras akan memilih nama default untuk Anda seperti dense_1 atau output_1 ). Dari perspektif TFMA, perilaku ini mirip dengan output untuk model multi-output meskipun model yang akan diestimasi mungkin hanya untuk model tunggal. Untuk memperhitungkan perbedaan ini, diperlukan langkah tambahan untuk mengatur nama keluaran. Namun, tiga opsi yang sama berlaku sebagai estimator.
Berikut ini adalah contoh perubahan yang diperlukan pada konfigurasi berbasis estimator:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
Bagaimana cara menyiapkan TFMA agar berfungsi dengan prediksi yang telah dihitung sebelumnya (yaitu model-agnostik)? ( TFRecord dan tf.Example )
Untuk mengonfigurasi TFMA agar berfungsi dengan prediksi yang telah dihitung sebelumnya, tfma.PredictExtractor default harus dinonaktifkan dan tfma.InputExtractor harus dikonfigurasi untuk mengurai prediksi bersama dengan fitur input lainnya. Hal ini dilakukan dengan mengonfigurasi tfma.ModelSpec dengan nama kunci fitur yang digunakan untuk prediksi bersama dengan label dan bobot.
Berikut contoh pengaturannya:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
Lihat metrik untuk informasi selengkapnya tentang metrik yang dapat dikonfigurasi.
Perhatikan bahwa meskipun tfma.ModelSpec sedang dikonfigurasi, model sebenarnya tidak digunakan (yaitu tidak ada tfma.EvalSharedModel ). Panggilan untuk menjalankan analisis model mungkin terlihat seperti berikut:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
Bagaimana cara menyiapkan TFMA agar berfungsi dengan prediksi yang telah dihitung sebelumnya (yaitu model-agnostik)? ( pd.DataFrame )
Untuk kumpulan data kecil yang dapat ditampung dalam memori, alternatif dari TFRecord adalah pandas.DataFrame s. TFMA dapat beroperasi pada pandas.DataFrame menggunakan API tfma.analyze_raw_data . Untuk penjelasan tentang tfma.MetricsSpec dan tfma.SlicingSpec , lihat panduan pengaturan . Lihat metrik untuk informasi selengkapnya tentang metrik yang dapat dikonfigurasi.
Berikut contoh pengaturannya:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
Metrik
Jenis metrik apa yang didukung?
TFMA mendukung beragam metrik termasuk:
- metrik regresi
- metrik klasifikasi biner
- metrik klasifikasi multi-kelas/multi-label
- metrik rata-rata mikro / rata-rata makro
- metrik berbasis kueri/peringkat
Apakah metrik dari model multi-output didukung?
Ya. Lihat panduan metrik untuk detail selengkapnya.
Apakah metrik dari beberapa model didukung?
Ya. Lihat panduan metrik untuk detail selengkapnya.
Bisakah pengaturan metrik (nama, dll) disesuaikan?
Ya. Pengaturan metrik dapat disesuaikan (misalnya menetapkan ambang batas tertentu, dll) dengan menambahkan pengaturan config ke konfigurasi metrik. Lihat panduan metrik untuk mengetahui detail selengkapnya.
Apakah metrik khusus didukung?
Ya. Baik dengan menulis implementasi tf.keras.metrics.Metric khusus atau dengan menulis implementasi beam.CombineFn khusus. Panduan metrik memiliki detail lebih lanjut.
Jenis metrik apa yang tidak didukung?
Selama metrik Anda dapat dihitung menggunakan beam.CombineFn , tidak ada batasan pada jenis metrik yang dapat dihitung berdasarkan tfma.metrics.Metric . Jika bekerja dengan metrik yang berasal dari tf.keras.metrics.Metric maka kriteria berikut harus dipenuhi:
- Statistik yang memadai untuk metrik pada setiap contoh dapat dihitung secara independen, kemudian menggabungkan statistik yang memadai ini dengan menambahkannya ke seluruh contoh, dan menentukan nilai metrik hanya dari statistik yang memadai ini.
- Misalnya, untuk akurasi, statistik yang memadai adalah "total benar" dan "total contoh". Anda dapat menghitung kedua angka ini untuk masing-masing contoh, dan menjumlahkannya untuk sekelompok contoh guna mendapatkan nilai yang tepat untuk contoh tersebut. Akurasi akhir dapat dihitung menggunakan "total contoh yang benar / total".
Pengaya
Bisakah saya menggunakan TFMA untuk mengevaluasi keadilan atau bias dalam model saya?
TFMA menyertakan add-on FairnessIndicators yang menyediakan metrik pasca-ekspor untuk mengevaluasi dampak bias yang tidak diinginkan dalam model klasifikasi.
Kustomisasi
Bagaimana jika saya memerlukan lebih banyak penyesuaian?
TFMA sangat fleksibel dan memungkinkan Anda menyesuaikan hampir semua bagian pipeline menggunakan Extractors , Evaluators , dan/atau Writers kustom. Abstraksi ini dibahas lebih rinci dalam dokumen arsitektur .
Pemecahan masalah, debugging, dan mendapatkan bantuan
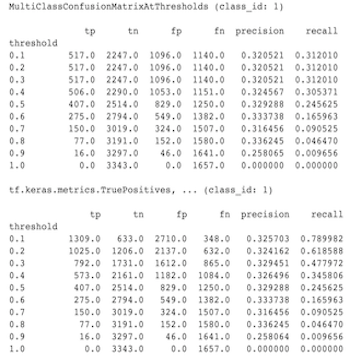
Mengapa metrik MultiClassConfusionMatrix tidak cocok dengan metrik ConfusionMatrix yang dibinarisasi
Ini sebenarnya adalah perhitungan yang berbeda. Binarisasi melakukan perbandingan untuk setiap ID kelas secara independen (yaitu prediksi untuk setiap kelas dibandingkan secara terpisah terhadap ambang batas yang disediakan). Dalam hal ini ada kemungkinan bagi dua kelas atau lebih untuk semuanya menunjukkan bahwa mereka cocok dengan prediksi karena nilai prediksinya lebih besar dari ambang batas (hal ini akan lebih terlihat pada ambang batas yang lebih rendah). Dalam kasus matriks konfusi multikelas, hanya ada satu nilai prediksi yang benar dan nilai tersebut cocok dengan nilai sebenarnya atau tidak. Ambang batas hanya digunakan untuk memaksa prediksi agar tidak cocok dengan kelas apa pun jika kurang dari ambang batas. Semakin tinggi ambang batasnya, semakin sulit untuk mencocokkan prediksi kelas biner. Demikian pula, semakin rendah ambang batasnya, semakin mudah untuk mencocokkan prediksi kelas biner. Artinya pada ambang batas > 0,5 nilai binarisasi dan nilai matriks multikelas akan lebih selaras dan pada ambang batas < 0,5 jaraknya akan semakin jauh.
Misalnya kita mempunyai 10 kelas dimana kelas 2 diprediksi dengan probabilitas 0,8, namun kelas sebenarnya adalah kelas 1 yang memiliki probabilitas 0,15. Jika melakukan binarisasi pada kelas 1 dan menggunakan ambang batas 0.1, maka kelas 1 akan dianggap benar (0.15 > 0.1) sehingga akan dihitung sebagai TP, Namun untuk kasus multikelas, kelas 2 akan dianggap benar (0.8 > 0,1) dan karena kelas 1 adalah kelas sebenarnya, maka ini akan dihitung sebagai FN. Karena pada ambang batas yang lebih rendah, lebih banyak nilai yang dianggap positif, secara umum akan terdapat jumlah TP dan FP yang lebih tinggi untuk matriks konfusi biner dibandingkan matriks konfusi multikelas, dan juga TN dan FN yang lebih rendah.
Berikut ini adalah contoh perbedaan yang diamati antara MultiClassConfusionMatrixAtThresholds dan jumlah terkait dari binarisasi salah satu kelas.
Mengapa metrik presisi@1 dan recall@1 saya memiliki nilai yang sama?
Pada nilai k teratas 1, presisi dan perolehan adalah hal yang sama. Precision sama dengan TP / (TP + FP) dan recall sama dengan TP / (TP + FN) . Prediksi teratas selalu positif dan akan cocok atau tidak cocok dengan label. Dengan kata lain, dengan N contoh, TP + FP = N . Namun, jika label tidak cocok dengan prediksi teratas, maka ini juga menyiratkan bahwa prediksi k non-top telah cocok dan dengan k teratas disetel ke 1, semua prediksi non-top 1 akan menjadi 0. Ini berarti FN harus (N - TP) atau N = TP + FN . Hasil akhirnya adalah precision@1 = TP / N = recall@1 . Perhatikan bahwa ini hanya berlaku bila ada satu label per contoh, bukan untuk multi-label.
Mengapa metrik mean_label dan mean_prediction saya selalu 0,5?
Hal ini kemungkinan besar disebabkan karena metrik dikonfigurasi untuk masalah klasifikasi biner, namun model mengeluarkan probabilitas untuk kedua kelas, bukan hanya satu. Hal ini biasa terjadi ketika API klasifikasi Tensorflow digunakan. Solusinya adalah memilih kelas yang Anda inginkan sebagai dasar prediksi dan kemudian melakukan binarisasi pada kelas tersebut. Misalnya:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
Bagaimana cara menafsirkan MultiLabelConfusionMatrixPlot?
Jika diberi label tertentu, MultiLabelConfusionMatrixPlot (dan MultiLabelConfusionMatrix terkait) dapat digunakan untuk membandingkan hasil label lain dan prediksinya ketika label yang dipilih benar-benar benar. Sebagai contoh, katakanlah kita mempunyai tiga kelas bird , plane , dan superman dan kita mengklasifikasikan gambar untuk menunjukkan apakah gambar tersebut mengandung satu atau lebih dari salah satu kelas tersebut. MultiLabelConfusionMatrix akan menghitung produk kartesius dari setiap kelas aktual terhadap kelas lainnya (disebut kelas prediksi). Perhatikan bahwa meskipun pasangannya adalah (actual, predicted) , kelas predicted tidak selalu menyiratkan prediksi positif, melainkan hanya mewakili kolom prediksi dalam matriks aktual vs prediksi. Misalnya, kita menghitung matriks berikut:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot memiliki tiga cara untuk menampilkan data ini. Dalam semua kasus, cara membaca tabel adalah baris demi baris dari sudut pandang kelas sebenarnya.
1) Jumlah Prediksi Total
Dalam hal ini, untuk baris tertentu (yaitu kelas sebenarnya) berapa jumlah TP + FP untuk kelas lainnya. Untuk hitungan di atas maka tampilan kita adalah sebagai berikut:
| Burung yang diprediksi | Pesawat yang diprediksi | Superman yang diprediksi | |
|---|---|---|---|
| Burung yang sebenarnya | 6 | 4 | 2 |
| Pesawat sebenarnya | 4 | 4 | 4 |
| Manusia super yang sebenarnya | 5 | 5 | 4 |
Ketika gambar tersebut benar-benar berisi seekor bird kami memperkirakan 6 di antaranya dengan tepat. Pada saat yang sama kami juga memprediksi plane (benar atau salah) sebanyak 4 kali dan superman (benar atau salah) sebanyak 2 kali.
2) Hitungan Prediksi Salah
Dalam hal ini, untuk baris tertentu (yaitu kelas sebenarnya) berapa jumlah FP untuk kelas lainnya. Untuk hitungan di atas maka tampilan kita adalah sebagai berikut :
| Burung yang diprediksi | Pesawat yang diprediksi | Superman yang diprediksi | |
|---|---|---|---|
| Burung yang sebenarnya | 0 | 2 | 1 |
| Pesawat sebenarnya | 1 | 0 | 3 |
| Manusia super yang sebenarnya | 2 | 3 | 0 |
Ketika gambar tersebut benar-benar berisi seekor bird kami salah memperkirakan plane sebanyak 2 kali dan superman sebanyak 1 kali.
3) Hitungan Negatif Palsu
Dalam hal ini, untuk baris tertentu (yaitu kelas sebenarnya) berapakah jumlah FN untuk kelas lainnya. Untuk hitungan di atas maka tampilan kita adalah sebagai berikut :
| Burung yang diprediksi | Pesawat yang diprediksi | Superman yang diprediksi | |
|---|---|---|---|
| Burung yang sebenarnya | 2 | 2 | 4 |
| Pesawat sebenarnya | 1 | 4 | 3 |
| Manusia super yang sebenarnya | 2 | 2 | 5 |
Ketika gambar tersebut benar-benar berisi seekor bird kami gagal memprediksinya sebanyak 2 kali. Pada saat yang sama, kami gagal memprediksi plane sebanyak 2 kali dan superman sebanyak 4 kali.
Mengapa saya mendapat pesan kesalahan tentang kunci prediksi tidak ditemukan?
Beberapa model mengeluarkan prediksinya dalam bentuk kamus. Misalnya, penduga TF untuk masalah klasifikasi biner mengeluarkan kamus yang berisi probabilities , class_ids , dll. Dalam kebanyakan kasus, TFMA memiliki default untuk menemukan nama kunci yang umum digunakan seperti predictions , probabilities , dll. Namun, jika model Anda sangat disesuaikan mungkin kunci keluaran dengan nama yang tidak diketahui oleh TFMA. Dalam kasus ini, pengaturan prediciton_key harus ditambahkan ke tfma.ModelSpec untuk mengidentifikasi nama kunci tempat output disimpan.