
- Opis :
Zbiór danych opisany po raz pierwszy w sekcji „Obiekty 3D Stanforda” w artykule Disentangling by Subspace Diffusion . Dane obejmują 100 000 renderowań każdego obiektu Królika i Smoka z Repozytorium Skanowania 3D Stanforda . W przyszłości może zostać dodanych więcej obiektów, ale w artykule wykorzystano tylko Króliczka i Smoka. Każdy obiekt jest renderowany z równomiernie próbkowanym oświetleniem z punktu na 2-sferze i równomiernie próbkowanym obrotem 3D. Prawdziwe stany ukryte są dostarczane jako tablice NumPy wraz z obrazami. Oświetlenie jest podane jako 3-wektor z normą jednostkową, natomiast obrót jest podany zarówno jako kwaternion, jak i macierz ortogonalna 3x3.
Istnieje wiele podobieństw między S3O4D a istniejącymi zbiorami danych porównawczych ML, takimi jak NORB , krzesła 3D , kształty 3D i wiele innych, które obejmują również renderowanie zestawu obiektów w różnych pozach i warunkach oświetlenia. Jednakże żaden z tych istniejących zbiorów danych nie obejmuje pełnej gamy obrotów w 3D – większość obejmuje jedynie podzbiór zmian elewacji i azymutu. Obrazy S3O4D są próbkowane równomiernie i niezależnie od pełnej przestrzeni obrotów i iluminacji, co oznacza, że zbiór danych zawiera obiekty odwrócone do góry nogami i oświetlone od tyłu lub od dołu. Wierzymy, że to sprawia, że S3O4D wyjątkowo nadaje się do badań modeli generatywnych, w których przestrzeń ukryta ma nietrywialną topologię, a także do ogólnych metod uczenia się rozmaitości, w których ważna jest krzywizna rozmaitości.
Dodatkowa dokumentacja : Eksploruj w dokumentach z kodem
Strona główna : https://github.com/deepmind/deepmind-research/tree/master/geomancer#stanford-3d-objects-for-disentangling-s3o4d
Kod źródłowy :
tfds.datasets.s3o4d.BuilderWersje :
-
1.0.0(domyślnie): Wersja pierwsza.
-
Rozmiar pobierania :
911.68 MiBRozmiar zbioru danych :
1.01 GiBAutomatyczne buforowanie ( dokumentacja ): Nie
Podziały :
| Podział | Przykłady |
|---|---|
'bunny_test' | 20 000 |
'bunny_train' | 80 000 |
'dragon_test' | 20 000 |
'dragon_train' | 80 000 |
- Struktura funkcji :
FeaturesDict({
'illumination': Tensor(shape=(3,), dtype=float32),
'image': Image(shape=(256, 256, 3), dtype=uint8),
'label': ClassLabel(shape=(), dtype=int64, num_classes=2),
'pose_mat': Tensor(shape=(3, 3), dtype=float32),
'pose_quat': Tensor(shape=(4,), dtype=float32),
})
- Dokumentacja funkcji :
| Funkcja | Klasa | Kształt | Typ D | Opis |
|---|---|---|---|---|
| FunkcjeDykt | ||||
| oświetlenie | Napinacz | (3,) | pływak32 | |
| obraz | Obraz | (256, 256, 3) | uint8 | |
| etykieta | Etykieta klasy | int64 | ||
| pozy_mat | Napinacz | (3, 3) | pływak32 | |
| pozycja_quat | Napinacz | (4,) | pływak32 |
Klucze nadzorowane (zobacz dokument
as_supervised):NoneRysunek ( tfds.show_examples ):
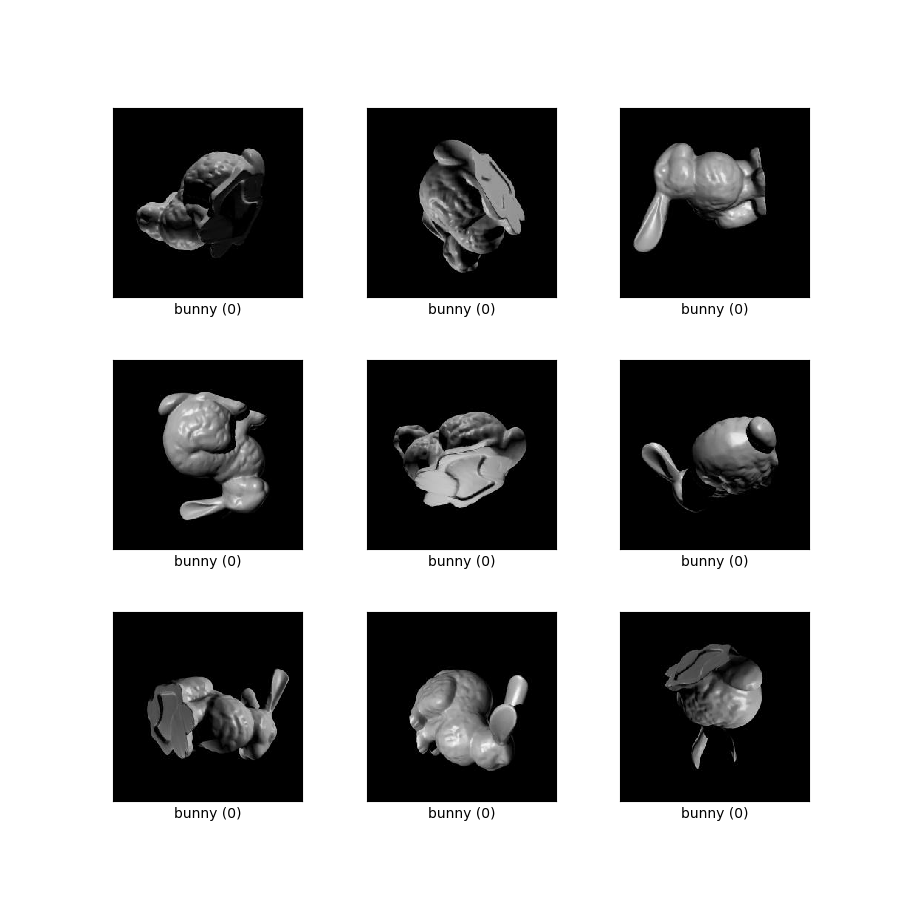
- Przykłady ( tfds.as_dataframe ):
- Cytat :
@article{pfau2020disentangling,
title={Disentangling by Subspace Diffusion},
author={Pfau, David and Higgins, Irina and Botev, Aleksandar and Racani\`ere,
S{\'e}bastian},
journal={Advances in Neural Information Processing Systems (NeurIPS)},
year={2020}
}