
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này trình bày cách tạo hình ảnh của các chữ số viết tay bằng cách sử dụng Mạng đối phương tạo ra lợi ích sâu sắc (DCGAN). Mã được viết bằng API tuần tự Keras với vòng lặp đào tạo tf.GradientTape .
GAN là gì?
Mạng đối thủ chung (GAN) là một trong những ý tưởng thú vị nhất trong khoa học máy tính ngày nay. Hai mô hình được đào tạo đồng thời bởi một quy trình đối đầu. Một máy phát điện ("nghệ sĩ") học cách tạo ra những hình ảnh giống như thật, trong khi một người phân biệt ("nhà phê bình nghệ thuật") học cách phân biệt hình ảnh thật với hình ảnh giả.
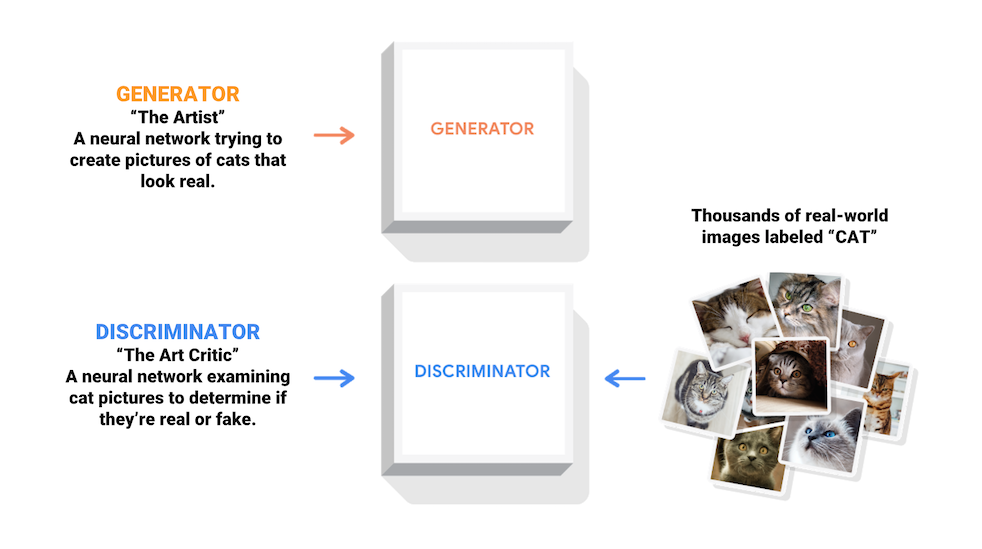
Trong quá trình đào tạo, bộ tạo hình ảnh dần dần trở nên tốt hơn trong việc tạo ra các hình ảnh giống như thật, trong khi bộ phân biệt trở nên tốt hơn trong việc phân biệt chúng. Quá trình đạt đến trạng thái cân bằng khi người phân biệt không còn phân biệt được ảnh thật với ảnh giả.
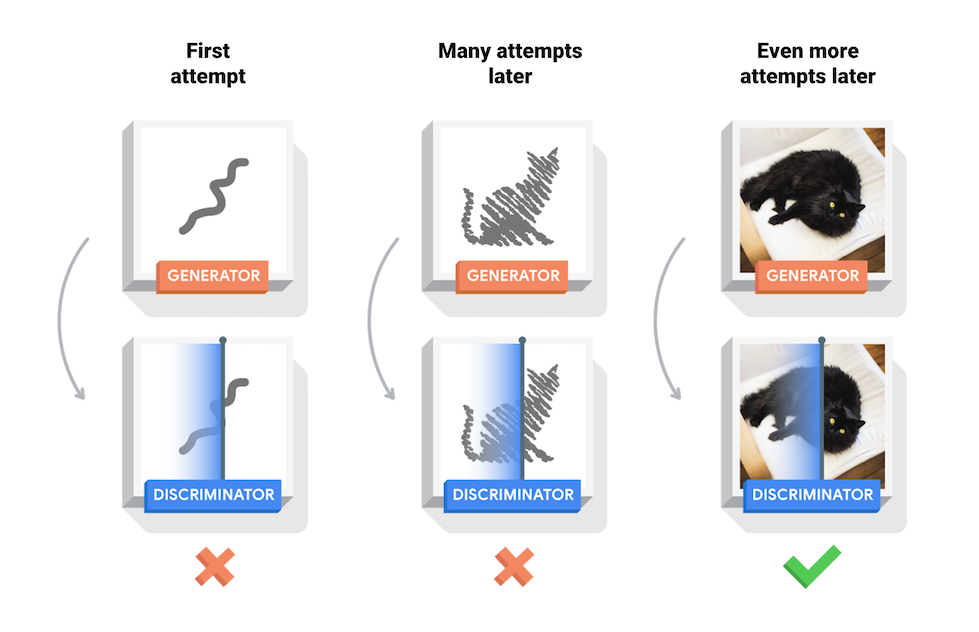
Sổ ghi chép này trình bày quá trình này trên tập dữ liệu MNIST. Hoạt ảnh sau đây cho thấy một loạt hình ảnh được tạo ra bởi trình tạo khi nó được đào tạo trong 50 kỷ nguyên. Các hình ảnh bắt đầu như nhiễu ngẫu nhiên và ngày càng giống với các chữ số viết tay theo thời gian.

Để tìm hiểu thêm về GAN, hãy xem khóa học Giới thiệu về Học sâu của MIT.
Thành lập
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Tải và chuẩn bị tập dữ liệu
Bạn sẽ sử dụng tập dữ liệu MNIST để huấn luyện trình tạo và trình phân biệt. Trình tạo sẽ tạo ra các chữ số viết tay giống với dữ liệu MNIST.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
Tạo các mô hình
Cả trình tạo và trình phân biệt đều được xác định bằng cách sử dụng API tuần tự Keras .
Máy phát điện
Trình tạo sử dụng các lớp tf.keras.layers.Conv2DTranspose (lấy mẫu ngược) để tạo ra hình ảnh từ một hạt giống (nhiễu ngẫu nhiên). Bắt đầu với một lớp Dense lấy hạt giống này làm đầu vào, sau đó lấy mẫu nhiều lần cho đến khi bạn đạt được kích thước hình ảnh mong muốn là 28x28x1. Lưu ý kích hoạt tf.keras.layers.LeakyReLU cho mỗi lớp, ngoại trừ lớp đầu ra sử dụng tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
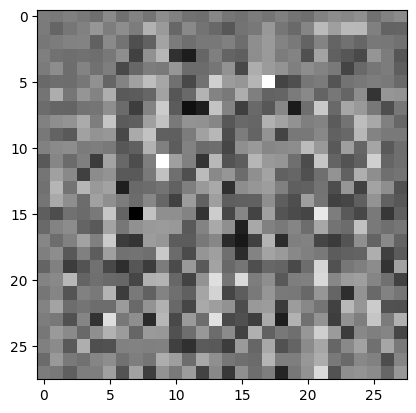
Sử dụng trình tạo (chưa được đào tạo) để tạo hình ảnh.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>
Người phân biệt đối xử
Bộ phân biệt là bộ phân loại hình ảnh dựa trên CNN.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Sử dụng bộ phân biệt (chưa được đào tạo) để phân loại các hình ảnh được tạo là thật hay giả. Người mẫu sẽ được đào tạo để xuất ra các giá trị dương cho ảnh thật và giá trị âm cho ảnh giả.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
Xác định sự mất mát và tối ưu hóa
Xác định chức năng mất mát và trình tối ưu hóa cho cả hai mô hình.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Mất người phân biệt đối xử
Phương pháp này xác định mức độ mà người phân biệt có thể phân biệt hình ảnh thật với hàng giả. Nó so sánh các dự đoán của bộ phân biệt trên các hình ảnh thực với một mảng 1 và các dự đoán của bộ phân biệt trên các ảnh giả (được tạo) với một mảng 0.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Mất máy phát điện
Tổn thất của máy phát điện xác định mức độ nó có thể đánh lừa người phân biệt. Bằng trực giác, nếu bộ tạo hoạt động tốt, người phân biệt sẽ phân loại các hình ảnh giả là thật (hoặc 1). Tại đây, hãy so sánh các quyết định phân biệt đối xử trên các hình ảnh được tạo với một mảng 1s.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
Trình phân biệt và trình tối ưu hóa trình tạo khác nhau vì bạn sẽ đào tạo hai mạng riêng biệt.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Lưu các điểm kiểm tra
Sổ tay này cũng trình bày cách lưu và khôi phục các mô hình, điều này có thể hữu ích trong trường hợp một nhiệm vụ đào tạo đang chạy dài bị gián đoạn.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Xác định vòng lặp đào tạo
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
Vòng lặp đào tạo bắt đầu với trình tạo nhận một hạt ngẫu nhiên làm đầu vào. Hạt giống đó được sử dụng để tạo ra một hình ảnh. Sau đó, bộ phân biệt được sử dụng để phân loại ảnh thật (được vẽ từ tập huấn luyện) và ảnh giả (được tạo ra bởi bộ tạo). Sự mất mát được tính toán cho từng mô hình này và các độ dốc được sử dụng để cập nhật bộ tạo và bộ phân biệt.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Tạo và lưu hình ảnh
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Đào tạo mô hình
Gọi phương thức train() được định nghĩa ở trên để huấn luyện đồng thời bộ tạo và bộ phân biệt. Lưu ý, việc đào tạo GAN có thể phức tạp. Điều quan trọng là bộ tạo và bộ phân biệt không chế ngự lẫn nhau (ví dụ: chúng đào tạo với tốc độ tương tự).
Khi bắt đầu quá trình đào tạo, các hình ảnh được tạo ra trông giống như nhiễu ngẫu nhiên. Khi quá trình đào tạo tiến triển, các chữ số được tạo ra sẽ ngày càng giống thật. Sau khoảng 50 kỷ nguyên, chúng giống với các chữ số MNIST. Quá trình này có thể mất khoảng một phút / kỷ nguyên với cài đặt mặc định trên Colab.
train(train_dataset, EPOCHS)

Khôi phục điểm kiểm tra mới nhất.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
Tạo ảnh GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Sử dụng imageio để tạo ảnh gif động bằng cách sử dụng các hình ảnh được lưu trong quá trình đào tạo.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Bước tiếp theo
Hướng dẫn này đã chỉ ra mã hoàn chỉnh cần thiết để viết và đào tạo một GAN. Bước tiếp theo, bạn có thể muốn thử nghiệm với một tập dữ liệu khác, chẳng hạn như tập dữ liệu Quy mô lớn thuộc tính CelebA (CelebA) có sẵn trên Kaggle . Để tìm hiểu thêm về GAN, hãy xem Hướng dẫn NIPS 2016: Mạng đối thủ chung .